
证券时报
2026-03-14 12:38


字节跳动发布豆包大模型,将定价调为0.0008元/千Tokens,称该定价低于行业均价99.3%,激起了BAT大模型集体降价的回应。
阿里打出“开源+降价”组合拳,通义千问部分产品直接降至0.0005元/千Tokens,比豆包大模型的价格更低;百度则将调用量最大的两大主流大模型免费;腾讯云则主打大模型应用“零门槛”,不仅将基础版的混元-lite直接免费,还对全面依赖混元模型进行的业务给予全量免费支持的福利大包。
大模型极速降价,意味着厂商需要在定制和服务等应用层面发力,以实现营收,而B端用户调用大模型的算力成本快速下降,会催生出一个AI应用繁荣的新时代吗?
来源:新财富杂志(ID:xcfplus)
作者:姬婧瑛
大模型降价的风,终于吹到了大厂。
5月15日,字节跳动正式发布豆包大模型,并披露豆包主力模型在企业市场(to B)的定价为0.0008元/千Tokens,即以0.8厘的价格可以处理1500多个汉字,较行业平均价格便宜99.3%。由此推算,此前行业平均价格为0.114元/千Tokens。
这个较“行业平均价格便宜99.3%”,刺激到了BAT。
5月21日,阿里、百度先后官宣降价,百度文心大模型两大主力模型全面免费,阿里通义大模型全面降价;5月22日,腾讯跟进降价。
科技大厂,打起价格战,跟街边商贩一个风格。
大模型降价,这是AI进入普惠时代的关键一步。
01
针对API调用算力贵的痛点,大模型集体降价
2022年末,Chat-GPT爆火出圈以来,国内百模大战如火如荼,互联网大厂通过云服务落地的大模型,被无数的B端用户使用。而Chat-GPT4、文心一言、通义千问、KIMI等基于大模型能力的问答应用,让更多C端用户切实感知到大模型的“魅力”。
如今,大模型厂商之间的竞争,从比硬件、卷参数、争用户,进入了价格的较量。
大模型降价为何会如此受关注?
打个比方,大模型的数据调用,类似于智能手机使用的流量。大模型调用API降价,类似于智能机发端时期,电信服务商集体降低流量价格。过去10年,流量价格的下降,间接催生了智能终端应用(APP)的大繁荣。
过去一年,大模型爆发、AI数据调用量井喷、英伟达GPU芯片价格暴涨等年度热词,都指向一个共同的指标,就是大模型API接口调用算力,贵、很贵、非常贵。
例如,在大模型一次输入10万汉字的文本,大概需要调用大模型7万Tokens,按行业大模型lite平均0.0008元/千Tokens的价格估算,一次输入10万字的成本是0.056元,月之暗面的Kimi此前宣称已经可以支持200万字无损上下文,那意味着,单个用户单次成本都超过1元。大模型成本之高,可见一斑。
今年5月以来,多个大模型推出低价产品或降价。
5月6日,幻方量化宣布,旗下深度求索(DeepSeek)正式开源第二代MoE模型DeepSeek-V2,API定价为:输入1元/百万tokens、输出2元/百万tokens,价格为GPT-4-Turbo的近1%。
5月11日,智谱宣布,其个人版GLM-3Turbo模型产品调用价格从5元/百万tokens降低至1元/百万tokens,价格打了2折。
5月13日,OpenAI推出GPT4o,它在英语文本和代码上与GPT-4 Turbo性能相当,向全部用户免费,API调用速度比GPT-4快两倍,但价格减半。
这波降价风潮,引起了字节跳动、阿里、百度、腾讯的快速跟进。
B端用户通过API接口调用大模型的算力,大模型降价,可以粗略理解为算力降价。调用大模型的成本降低,有利于更多的下游用户直接采用大模型去定向开发个性化的应用。这样,最大可能避免企业在大模型底层硬件、软件层面的重复建设,推动整个行业向下游应用端发力。
百度李彦宏就曾公开表示,不断地重复开发基础大模型,是对社会资源的极大浪费。他指出,只有当模型的参数规模足够大,训练数据量足够多,并且能够不断投入,持续迭代,才能够产生“智能涌现”。而没有“智能涌现”能力的专用大模型,价值非常有限。
“智能涌现”即大模型触类旁通的能力,也就是大模型能够自主学会那些没有被教过的东西,简单说,就是“不教也会”,这是大模型进化的内在逻辑。大模型要具备“智能涌现”的能力,前提就是足够海量的数据输入和训练。
无论是比拼硬件、软件、参数、活跃用户数,还是降价,大模型厂商最终争夺的都是数据体量。数据投喂规模越大,大模型“智能涌现”的能力越强,这与算法进化的基本逻辑一致。
因此,大模型供应商阿里、百度、腾讯、字节跳动等,要想和电信服务商一样,成为AI时代“基础设施”供应商,就需要基于自身优势,提供从底层GPU、服务器,到中层软件应用,再到整体解决方案,甚至大模型定制等不同梯次的服务,覆盖不同的客户需求。
目前,BAT的大模型均通过智能云落地,我们可以从各家云服务业务营收增速,大模型迭代速度、参数量、调用量,来管窥大模型业务的发展情况。
02
阿里:通义千问打出“开源+降价”组合拳,1元钱可以调用200万Tokens
作为国内智能云的带头大哥,可以走出国门与谷歌云、微软云扳手腕的阿里云,走的是开放、开源的路线。
“让云成为水和电一样的公共服务”是阿里云的定位,基于云服务落地的大模型,也是公共服务之一。2023年底,阿里巴巴集团CEO吴泳铭为阿里云确定了“AI驱动,公共云优先”战略。
通过与大部分头部大模型公司合作,以及与自研的通义大模型共同成长,带动了阿里云的增长。2023年度,阿里云在亚太地区IaaS(基础设施即服务)市场的份额达到22.2%,排名第一,同比提升0.8个百分点。
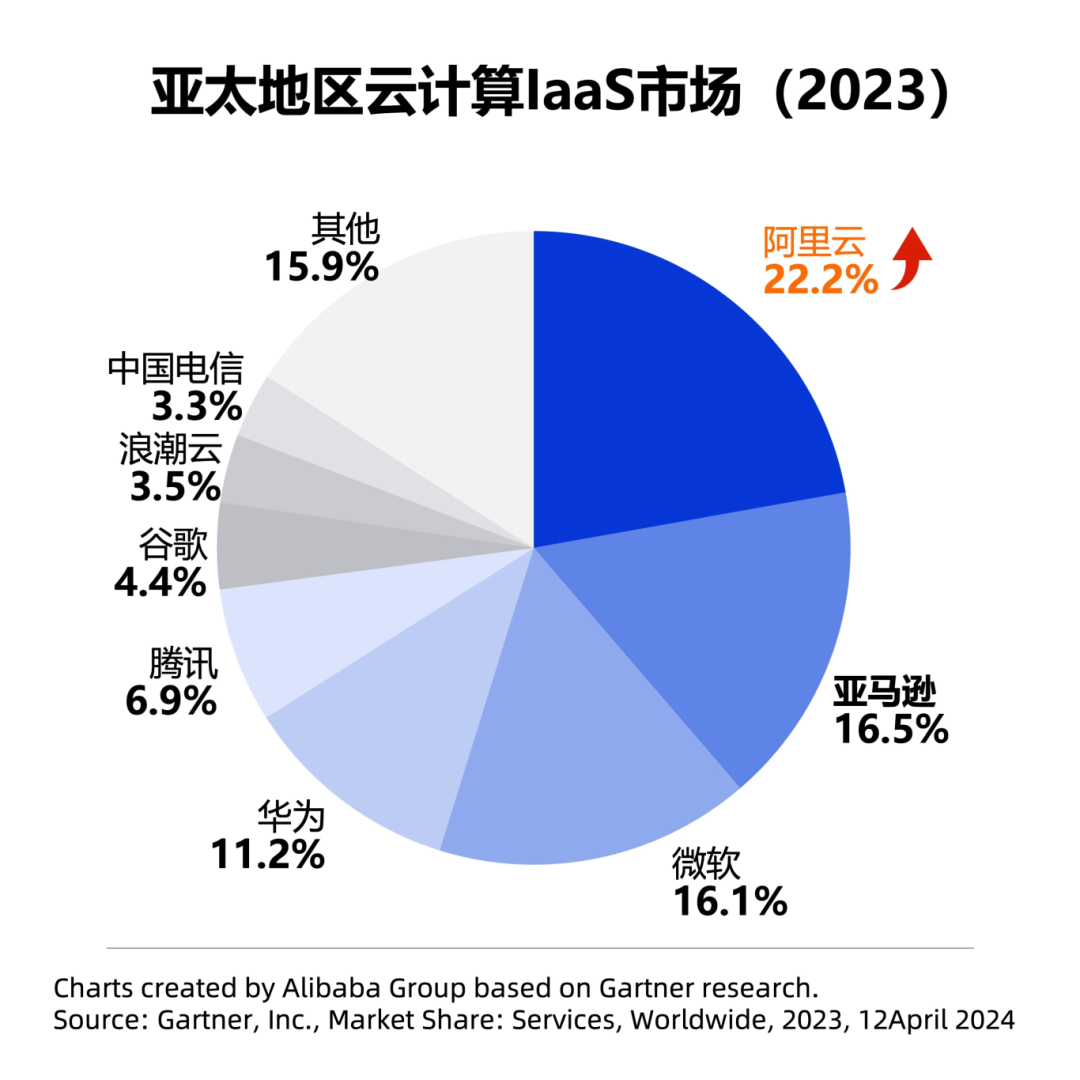
近年,阿里云与通义大模型接连通过降价、开源等组合拳,来争夺市场用户。
大模型训练和迭代成本昂贵,绝大多数的AI开发者和中小企业都无法负担这个成本。2023年8月,阿里通义大模型开源。截至2024年5月9日,其开源模型下载量已超过700万次,阿里通义同时宣布,为不同场景、不同需求的用户,推出参数规模横跨5亿到1100亿的八款大语言模型。
小尺寸模型如0.5B(Billion,10亿参数)、1.8B、4B、7B、14B,可在手机、PC等端侧设备部署;大尺寸模型如72B、110B,能支持企业级和科研级的应用;中等尺寸如32B,试图在性能、效率和内存占用之间找到最具性价比的平衡点。
其中,1100亿参数开源模型Qwen1.5-110B,在MMLU、TheoremQA、GPQA等基准测评中超越了脸书(Meta)的Llama-3-70B模型,在HuggingFace推出的开源大模型排行榜Open LLM Leaderboard上,冲上了榜首。
此外,通义还开源了视觉理解模型Qwen-VL、音频理解模型Qwen-Audio、代码模型CodeQwen1.5-7B、混合专家模型Qwen1.5-MoE。
大模型开源后,通义千问又使出了降价大招,部分大模型数据调用价格降幅达97%。降价后,1元钱可以调用200万Tokens,即0.0005元/千Tokens,比豆包大模型的价格更低。
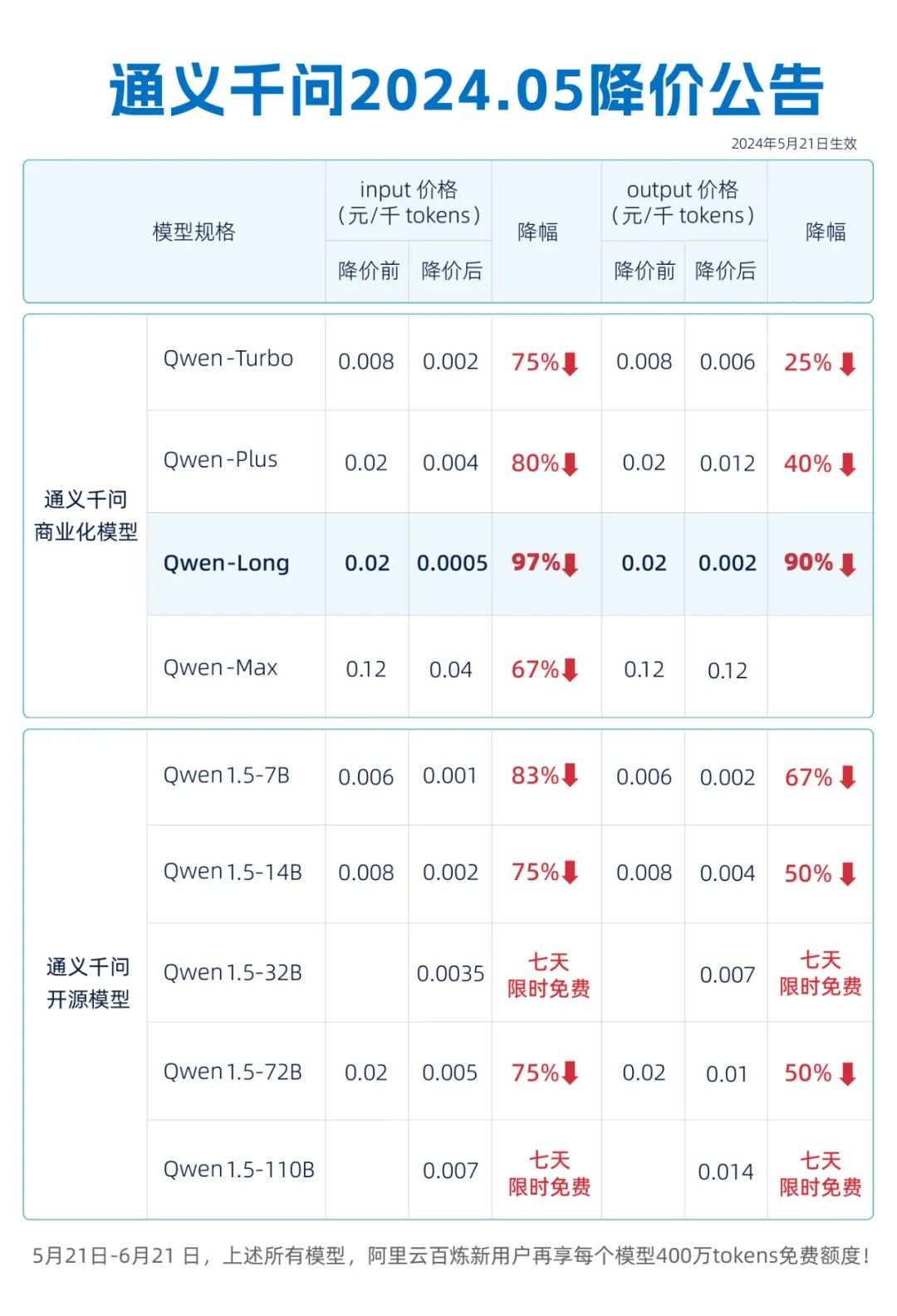
而此前,2月29日,阿里云宣布史上最大力度降价,100多款产品、500多个产品规格均价降低20%,最高降价55%。
4月,阿里云再次宣布,面对全球13个地域,500多个产品规格,全线下调产品价格,平均下降23%,最高下降59%。
云服务和大模型调用成本双双下降,有力推动了大模型企业客户的增长。最新数据显示,通义大模型通过阿里云服务企业客户超过9万,通过钉钉服务企业客户超过220万。小爱同学、小米汽车、微博、众安保险、完美世界游戏等已接入通义大模型。
有了客户增量,尽管产品大幅降价,阿里云也已实现稳定盈利。2024年一季度,阿里云录得营收255.95亿元,同比增长3%,其中AI相关收入实现三位数的增长,经调整的EBITA利润14.32亿元,同比增长45%。
阿里云不再是阿里集团的负担,进入稳定盈利周期。
03
百度:两大主流大模型免费,“模型+工具”家族比开源更有性价比
迈向生成式AI的第二年,百度正在推进用文心大模型重构To C和To B业务。
2024年一季度,百度优化AI原生应用开发工具AppBuilder和模型定制工具ModelBuilder,并在文心大模型旗舰版的3.5和4.0版本基础上,推出3款轻量级模型和2款特定场景模型,并上线AgentBuilder、AppBuilder和ModelBuilder三大开发工具,在云上形成“模型家族+两大开发工具”的组合。
目前,ModelBuilder已服务近10万家客户。
百度发文称,模型家族及上述工具的推出,为开发者和企业降低了开发门槛、提高开发和训练效率,并带来比开源模型更高的性价比。这是百度公开针对大模型“开源”的对比。
李彦宏公开表示,“模型推理是最重要的长期机会之一”,这将成为云业务的关键驱动力。
截至2024年4月,文心大模型API日调用量已达2亿次,去年12月时,该数据为5000万次,以此看,其实现了4个月4倍的增长。在中国,三星、荣耀、OPPO、vivo、小米等手机厂商均接入文心大模型API。
得益于大模型业务的增长,2024年一季度,百度智能云实现营收达47亿元,同比增长12%,并持续实现盈利(Non-GAAP)。其中,生成式AI贡献的收入比例达6.9%,占比逐步扩大。
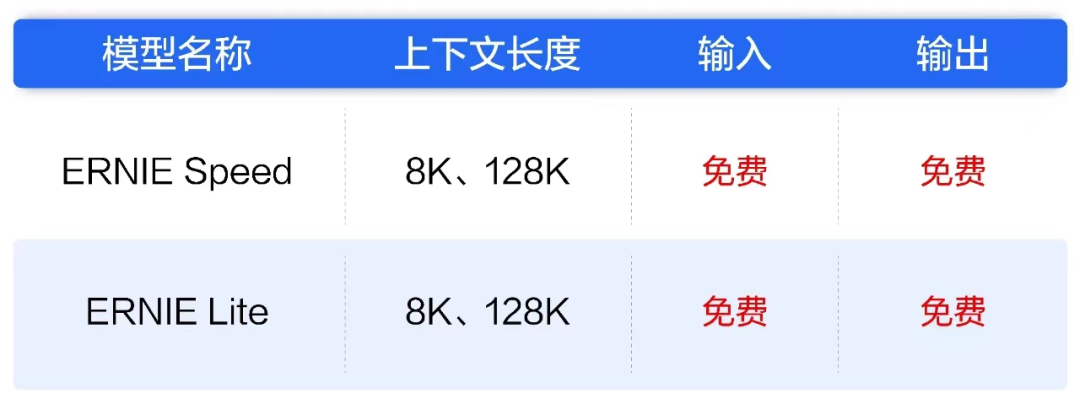
百度将调用量最大的两大主流大模型免费,可能最直接的影响是,日均收入减少200万元,但同时,也可能会带来更多的用户接入,衍生更多的收费定制服务。
04
腾讯:混元最新大模型价格全面下调,打造零门槛大模型应用
大模型落地产业,难在“应用”关。
5月17日,腾讯云生成式AI产业应用峰会上,腾讯云发布了大模型研发、应用产品的系列进展,直指将大模型应用降至“零门槛”。
腾讯混元大模型发布多个版本模型,如万亿参数的混元-pro、千亿参数混元-standard、百亿参数混元-lite等,通过腾讯云对外全量开放,满足企业客户、开发者在不同场景下的模型需求。
其中,混元-standard最新上线了支持256k超长上下文窗口的长文模型,具备单次处理超过38万字符的超长文本能力,能够应对金融、医疗、教育、出行等专业人士的数据处理需求。
同时,腾讯云还发布大模型知识引擎、图像创作引擎、视频创作引擎三大PaaS(平台即服务)工具,通过PaaS服务,简化数据接入、模型精调、应用开发流程,方便用户接入特定的生产场景。
这些低门槛或零门槛的开发工具,让大模型更好使用。腾讯混元大模型已在诸如微信读书、腾讯会议、腾讯广告等600多个内部业务和场景中落地使用,腾讯旗下协作SaaS(软件即服务)产品也已全面接入混元大模型。
更为重要的是,腾讯将其移动互联网时代“生态共建”的经验,平移到了AI时代,推出生成式AI生态计划,联合千家解决方案供应商、培育千家服务商和万家代理商,共同推动生成式AI技术深入产业全链条。
大模型新品发布仅5天后,腾讯将“当家产品”全面降价,可谓诚意满满。最基础的混元-lite免费;混元-standard打五折;具备超长文本处理能力的混元-standard-256K,输入价格直降近9成,输出价格打五折。
而如果是对腾讯大模型深度“依赖”的API分发(腾讯全域)模型,即全面依赖混元模型进行的业务,腾讯给予全量免费支持的福利大包。

值得一提的是,大模型“硬件”免费后,大模型厂商需要靠“软件和服务”来赚钱,倒逼大模型向更具竞争力的应用方向发力。
这样的变化,会催生出什么样的应用繁荣?这些AI应用又会如何改变我们的生活?大模型供应商们收入结构会发生什么样的变化?这些未知和问题,或会在大厂们半年报中显露端倪,敬请期待。
本文所提及的任何资讯和信息,仅为作者个人观点表达或对于具体事件的陈述,不构成推荐及投资建议。投资者应自行承担据此进行投资所产生的风险及后果。






《新财富》杂志于2001年3月创刊,专注资本市场深耕细作,“最佳分析师”“最佳董秘”“500创富榜”“最佳上市公司”“最佳投行”等权威专业评选和《德隆系》《明天帝国》《收割者》等经典研究案例影响深远。
新财富杂志社旗下主要新媒体平台包括:新财富杂志微博、新财富杂志公众号、新财富杂志视频号。
地址:深圳市福田区彩田路7006号深科技城A座43层
